adom-tts
Thin Rust CLI + webview playground for service-tts — Adom's shared edge-tts wrapper with pronunciation overrides + source-hash cache.
What's new in 0.1.2 — built-in auto-player
The CLI now plays its own mp3s. Stop authoring custom autoplay HTML or python3 -m http.server workarounds.
# One shot: synthesize and auto-play. CLI returns immediately (detached).
adom-tts say "Read me your latest answer, I'm driving." --out /tmp/x.mp3 --play
# Replay the newest history clip.
adom-tts play last
# Replay any history clip by full id or unique substring of its hash.
adom-tts play 5f79f0
How it works. play (and say --play) spins up a one-shot tiny_http server bound to a 127.0.0.1 ephemeral port, serving the mp3 + a small autoplay page. The container's $VSCODE_PROXY_URI wraps the port into a Cloudflare-routable URL. The chosen surface — Hydrogen webview tab (default) or pup browser window — navigates to that URL. Same plumbing both surfaces, no port mappings, no clip-size limits, no base64 URL bloat.
Tab/window auto-closes when the audio's ended event fires (or a 5-min cap). Programmatic, not AI-driven — the binary handles cleanup. Override with ADOM_TTS_KEEP_OPEN=1 if you want the player to linger.
Surface precedence: --surface hydrogen|pup flag → $ADOM_TTS_SURFACE env → ~/.adom/tts/config.toml ([play] surface = "...") → "hydrogen" default.
Self-teaching hints. say without --play emits stderr hints pointing the AI at the auto-player and warning against the anti-patterns we've seen sessions fall into (custom HTML, port-add, etc.). Silenceable via ADOM_TTS_NO_HINTS=1.
Hands-free trigger phrases
When the user says "I'm driving", "read it to me", "can't read the screen", "in the car", "narrate the answer" — they CANNOT see your text response. Synthesize and --play. The skill front-matter lists the full trigger catalog.
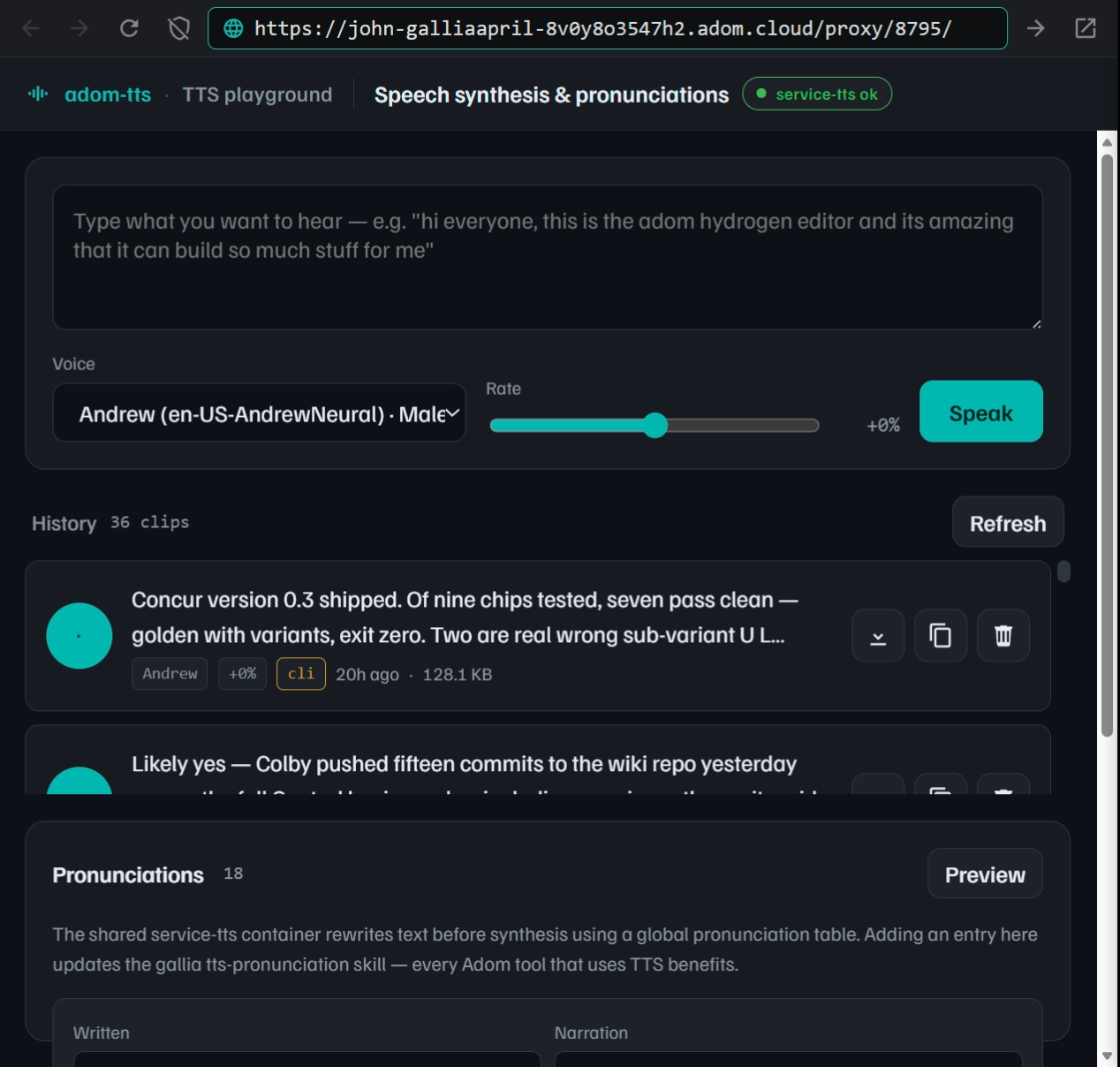
Playground webview (unchanged from 0.1.1)
adom-tts serve opens a Hydrogen webview panel. Type what you want to hear, pick a voice, hit Enter. Every clip you generate (or that any other tool drops via adom-tts say --history / adom-tts push) is saved to ~/.adom/tts/history/ and replayable from the list. Download, copy shareable URLs, delete — all per-clip.
Pronunciation authoring. A live view of the global pronunciation table sits next to the compose area. When your input contains a term that already has an override, a hint appears: "adom-tsci will be voiced as adom t s c i · global override". An Add form lets you propose new entries, with a Preview button that synthesizes raw + phoneticized forms back-to-back, and a Propose button that writes straight into gallia/skills/tts-pronunciation/pronunciations.json.
Everything is AI-drivable. Every UI action has an HTTP equivalent — POST /synth, GET /history, DELETE /history/:id, GET /pronunciations, POST /pronunciation/propose, GET /state, GET /console, POST /shutdown.
Install (Tier B)
Paste-into-Claude:
curl -fsSL https://wiki-ufypy5dpx93o.adom.cloud/static/apps/adom-tts/adom-tts \
-o /tmp/adom-tts && chmod +x /tmp/adom-tts \
&& sudo install -m 0755 /tmp/adom-tts /usr/local/bin/adom-tts \
&& adom-tts install \
&& adom-tts health
adom-tts install deploys the SKILL.md + adom-tts-build sibling skill + bash completions. Gallia's 30-min refresh hook keeps the installed version in sync with the wiki's pub_version.
CLI
# Synthesis + auto-play (the common case)
adom-tts say "Hello from adom-tsci" --out hello.mp3 --play
adom-tts say "narration" --out n.mp3 --voice en-US-AriaNeural --play
# Replay
adom-tts play last
adom-tts play /tmp/x.mp3 --wait # block until ended (max 5 min)
adom-tts play /tmp/x.mp3 --surface pup
# Synthesis only (rare — when you genuinely just need the file)
adom-tts say "for later" --out later.mp3
# Playground
adom-tts serve [--port 8795]
adom-tts push path/to/clip.mp3
# Pronunciations
adom-tts pron list
adom-tts pron add "adom-tsci" "adom t s c i" --reason "letter-by-letter forces 4-letter reading"
# Introspection
adom-tts voices | jq '.count'
adom-tts pronunciations | jq '.count'
adom-tts health
adom-tts config # current service URL + bake/env source
adom-tts config --show # also dump resolved play surface + config path
$ADOM_TTS_API overrides the baked-in service URL. Default voice is en-US-AndrewNeural — the house voice for every Adom demo.
Anti-patterns the new auto-player exists to prevent
- ❌
python3 -m http.server <port>to serve the mp3. Pup runs on the user's desktop; container localhost is unreachable. Hydrogen webviews have the same constraint. - ❌ Custom HTML with base64-inlined mp3 +
data:URL. Past 2 MB this hits Chrome's URL length limit. - ❌
adom-cli carbon containers port-addfor a permanent*.adom.cloudsubdomain. Total overkill for a one-shot. - ✅ Just use
--play. The binary handles surface, URL, autoplay, and cleanup.
Who uses this
demo-recording/voiceover/tour— everyone that renders narrationaci voice— backend precedence$ACI_VOICE_API → adom-tts CLI → edge-tts local fallback- Drive-mode users via Claude RC — synthesize + auto-play means hands-free answers
- Any new tool that needs spoken output should shell out to
adom-tts sayrather than calling edge-tts directly
Exit codes
| code | meaning |
|---|---|
0 | ok |
1 | invalid input (empty text, missing --out) |
2 | service unreachable — check adom-tts config or set $ADOM_TTS_API |
4 | service-side error (edge-tts failed, etc.) |
Source (private): adom-inc/adom-tts. Service backend: service-tts. Pronunciation source of truth: gallia/skills/tts-pronunciation/pronunciations.json.
